论文阅读 - How to best use Syntax in SRL
本文讨论如何把句法信息加入 SRL 任务。其中提到了三种方法:使用句法信息作为输入;使用句法信息组成 Multi-task;同时使用上述两种方法,组成 auto-encoder。本文使用 CoNLL’05 和 CoNLL’12 作为训练集进行测试。
Introduction
外部信息
将外部信息加入 NLP 任务的思想在近几年中趋势越发明显。关于这个问题,有三种主流的做法:
- 加入 Input:外部信息作为神经网络的额外输入特征。
- 作为 Output:神经网络在训练主任务的同时需要对这些信息进行 Multi-task 训练。
- Auto-encoder:同时将外部信息作为神经网络的 Input 和 Output。
但是这些研究主要停留在了一些浅层信息,例如将 POS 标签和序列标注任务结合。而那些标注句法依赖等等“较长”句法特征信息则没有被仔细研究。这篇文章就是针对这一点进行一个补充。
在这篇文章中,主要讨论了三个问题:
- 应该如何将句法信息加入作为word-level featrues?
- 如何最好地表达句法信息?
- 句法信息表达的选择对于结果有多少影响?
SRL System
一个语法标注系统能够提取 predicate-argument 结构。在研究早期句法信息一直是 SRL 的重要组成部分,然而当下的 SOTA 模型并没有显式地包含句法信息。这篇文章希望通过实验证明句法信息对于 SRL 系统的重要作用。
在这篇文章中,作者将外部信息表示为离散特征向量。其中有三类表示:
- Full-C:全成分树表示
- SRL-C:SRL-specific span 表示
- Dep:依赖树表示
Evaluation
对于不同的整合方式,在语料库 CoNLL’05 和 CoNLL’12 上进行测试获得结果
句法表示
Full-C
参照 Gomez-Rodrıguez and Vilares 提出的方法,将成分分析树进行向量化。为了表示这个提出下列标注:
- $n(wi)$:指$w_i$和$w{i+1}$间的共有父节点的数量。
- $l(w_i)$:编号最小的父节点的 non-terminal 标签。如果是 terminal,则为 S。
- $r(wi)$:$n(w_i) - n(w{i-1})$
通过记录所有节点的上述信息,可以完全还原成分分析树。示例如下:
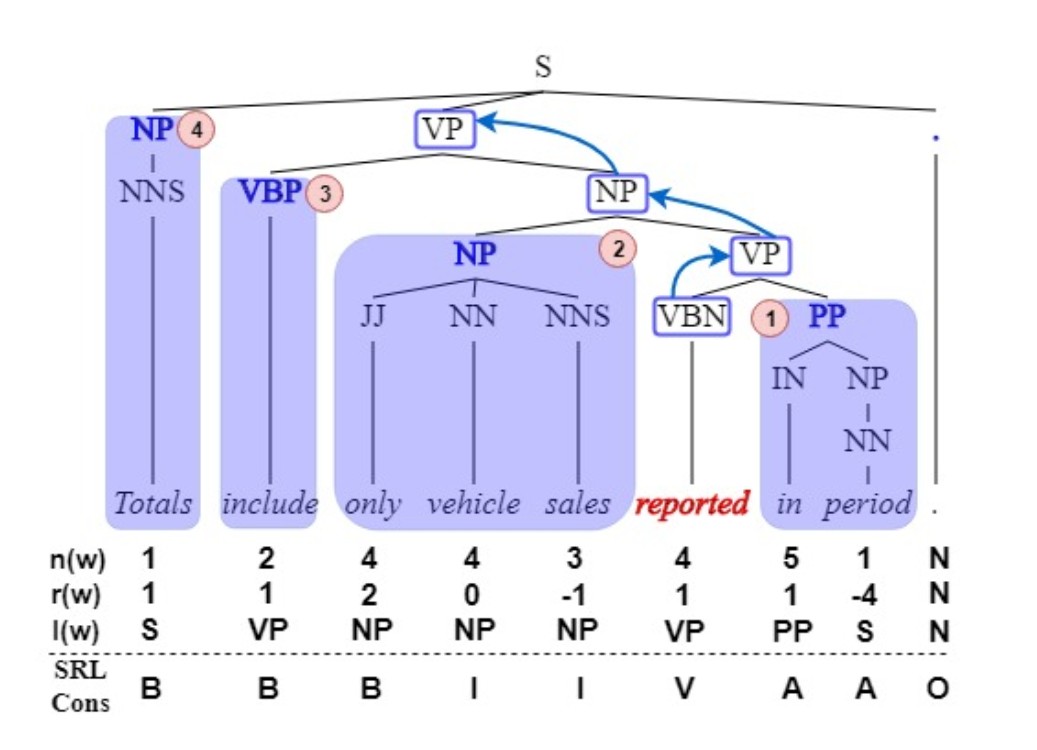
SRL-C
只有一小部分的成分分析树中的成分是发挥了作用的。这意味着将整个成分分析树都进行编码可能不是最优解。因此仅保留最有可能有利于标签分类的成分是必要的一个操作。为此,作者使用了剪枝算法,将其中的部分 argument 收集起来,并将无关的部分滤除。对于滤除的结果使用标准 BIO 标记法标记。
- O:单词在任何一个候选成份外
- B:单词是某一个候选成分的第一个单词
- I:单词在某一个候选成分中
- A:单词在一个介词短语中
- V:正在考察的 predicate 的核心动词
这个标记在上面例图中已经标明。
Dep
通过依赖树,编码的仍然是成分信息。其具有下列的标签:
- Left/Right:这个但错左右拥有的依赖数。
- Edge:这个单词是管辖这个词(左边/右边/不是)最依赖这个词的词。
- RG(Relative distance to governor):这个词与其 Governor 间的距离。
- DL(Dependent label):指向这个词的 denpendent 标签。
示例如下:
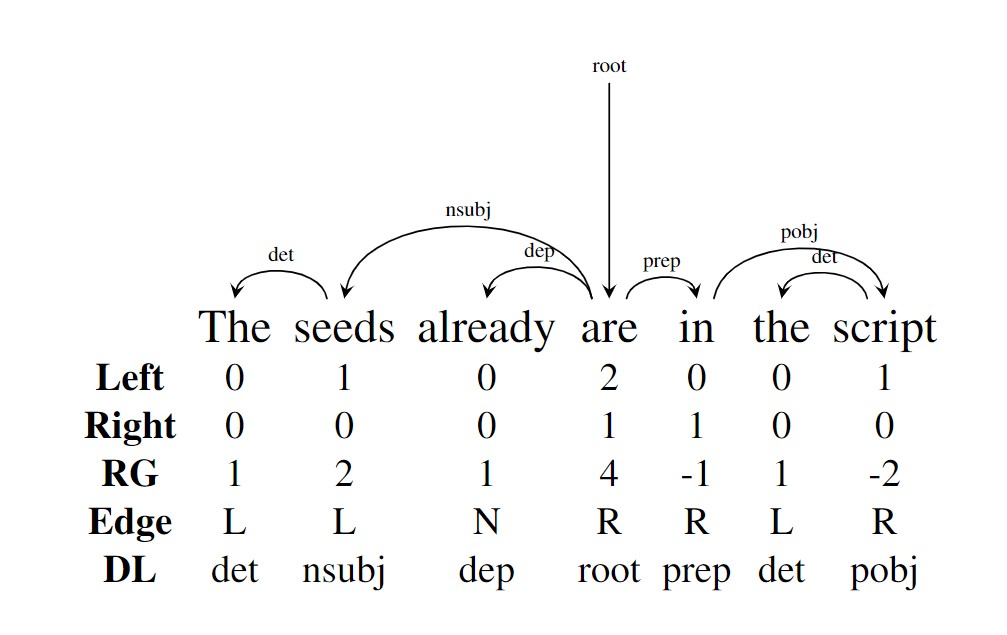
如何使用外部信息?
加入外部信息的方法如同前文所说,有三:
- Input:将外部信息和 ELMo 提供的词向量相连。其中依赖树通过将生成的成分树进行变换得到,以保证两种划分方法的一致性。
- Output:同时预测 SRL 和句法特征,最后使用的损失函数是这两部分的和。
- Anuto-encoder:将外部信息作为特征输入,并同时作为 multi-task 训练的对象,使得这个方法呈现出 encoder 的特性。
实验部分
实验一共进行了 10 组:“3 种使用外部信息的方法”x“3 种将文本句法特征向量化的方法” + 1 个 baseline。实验在 CoNLL’01 和 CoNLL’12 上进行。
主要结果
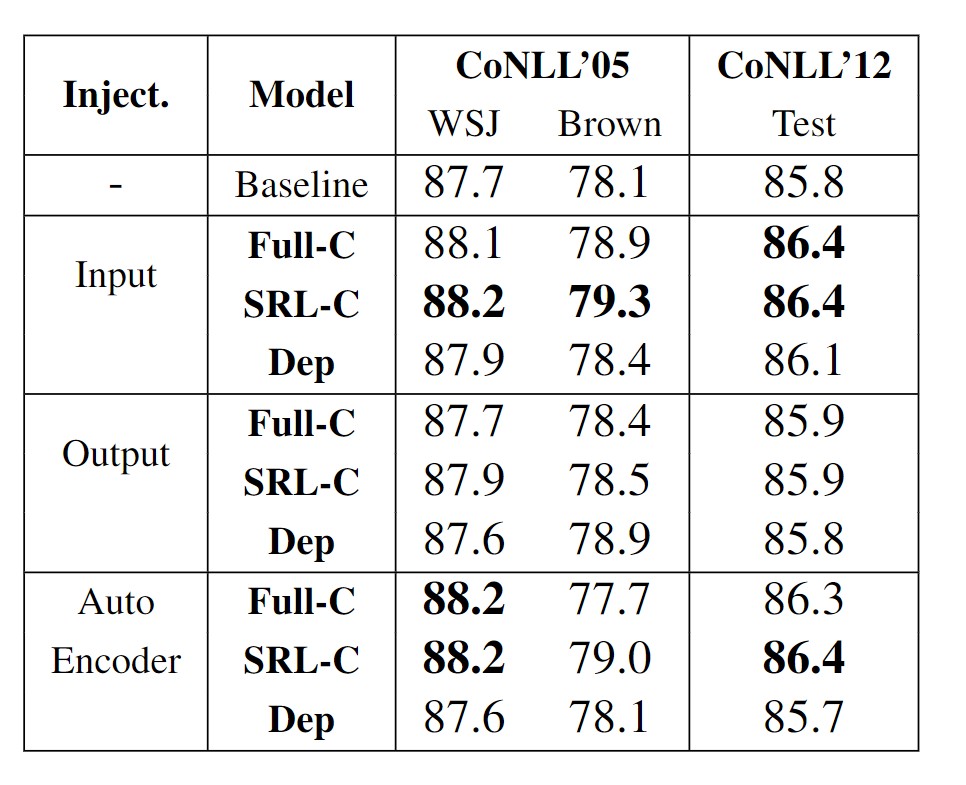
结果表示,句法信息确实是对 SRL 能力有积极提升作用。其中,Full-C 获得了更优于 Dep 的实验结果。作者认为这是由于成分树更加接近于 SRL 的信息。此外 SRL-C 的方法略好于 Full-C 方法,在集外预测时也更具优势。
并且使用 Multi-task 在这个任务中并没有体现出非常好的效果,而其馀两种方法效果相当。
与现有系统的对比
作者将本次实验中表现最为出色的 SRL-C used as Input 作为对比,和现有的各个工作进行对比。这个方法相较于现在已有的模型有略微的提升,但是结果并未明显胜出 ensemble 方法。